We recently composed a scraper that works to extract data of a static site. By a static site, we mean such a site that does not utilize JS scripting that loads or transforms on-site data.
If you are interested in a scrape JS-rendered site, please read the following: Scraping a Javascript-dependent website with puppeteer.
Technologies stack
- Node.js, the server-side JS environment. The main characteristic of Node.js is the code asynchronous execution.
- Apify SDK, the scalable web scraping and crawling library for JavaScript/Node.js. Let’s highlight its excellent characteristics:
- automatically scales a pool of headless Chrome/Puppeteer instances
- maintains queues of URLs to crawl (handled, pending) – this makes it possible to accommodate crawler possible failures and resumes.
- saves crawl results to a convenient [json] dataset (local or in the cloud)
- allows proxies rotation
We’ll use a Cheerio crawler of Apify to crawl and extract data off the target site. The target is https://www.ebinger-gmbh.com/.

 Question: What is Selenium web scraping?
Question: What is Selenium web scraping?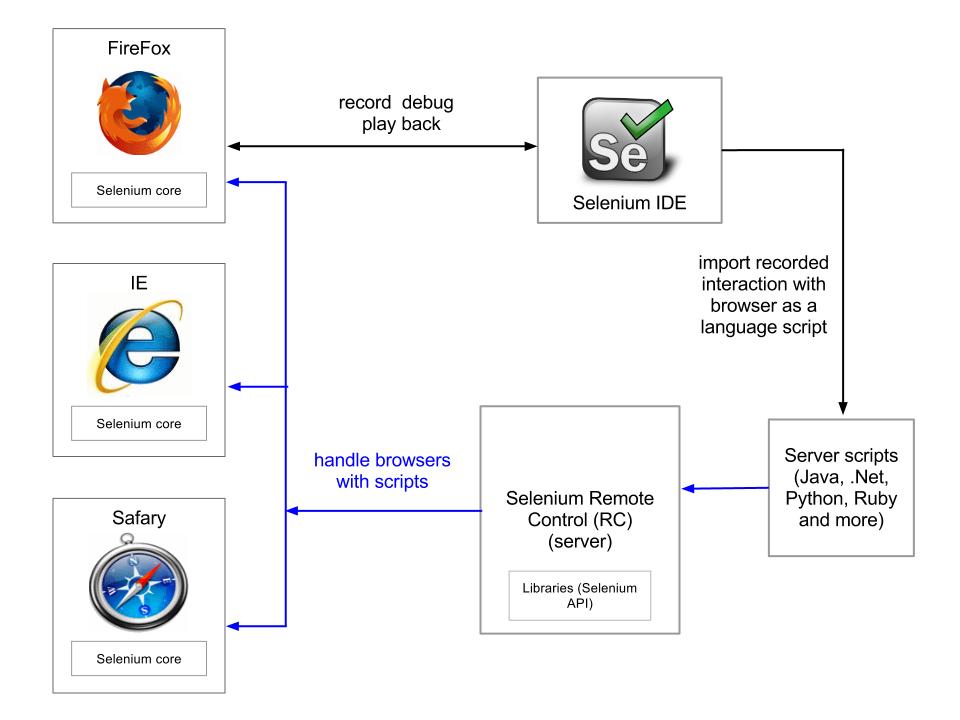

 My goal was to retrieve data from a web business directory.
My goal was to retrieve data from a web business directory.