We recently composed a scraper that works to extract data of a static site. By a static site, we mean such a site that does not utilize JS scripting that loads or transforms on-site data.
Technologies stack
- Node.js, the server-side JS environment. The main characteristic of Node.js is the code asynchronous execution.
- Apify SDK, the scalable web scraping and crawling library for JavaScript/Node.js. Let’s highlight its excellent characteristics:
- automatically scales a pool of headless Chrome/Puppeteer instances
- maintains queues of URLs to crawl (handled, pending) – this makes it possible to accommodate crawler possible failures and resumes.
- saves crawl results to a convenient [json] dataset (local or in the cloud)
- allows proxies rotation
We’ll use a Cheerio crawler of Apify to crawl and extract data off the target site. The target is https://www.ebinger-gmbh.com/.
Get categories links – initial urls for crawler
First, we find all the categories’ links of the website. For that we used the Scraper, Google Chrome extension:
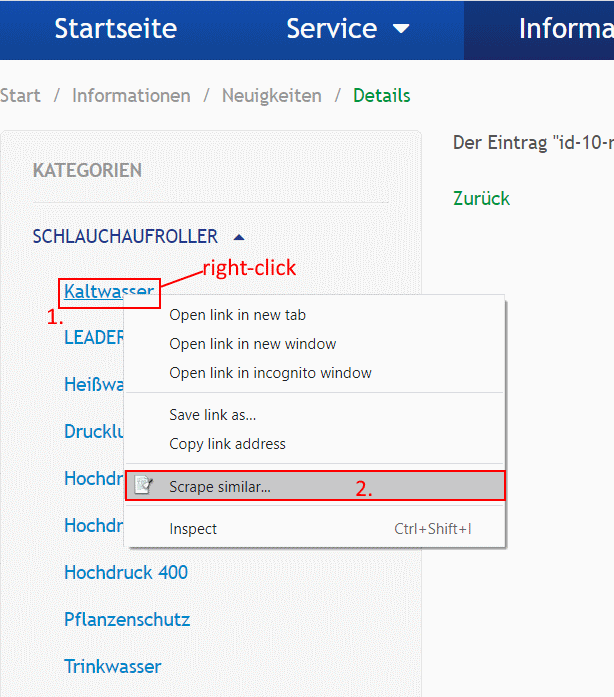
This will provide us with some links based on Xpath. Edit Xpath to have all possible categories be included.
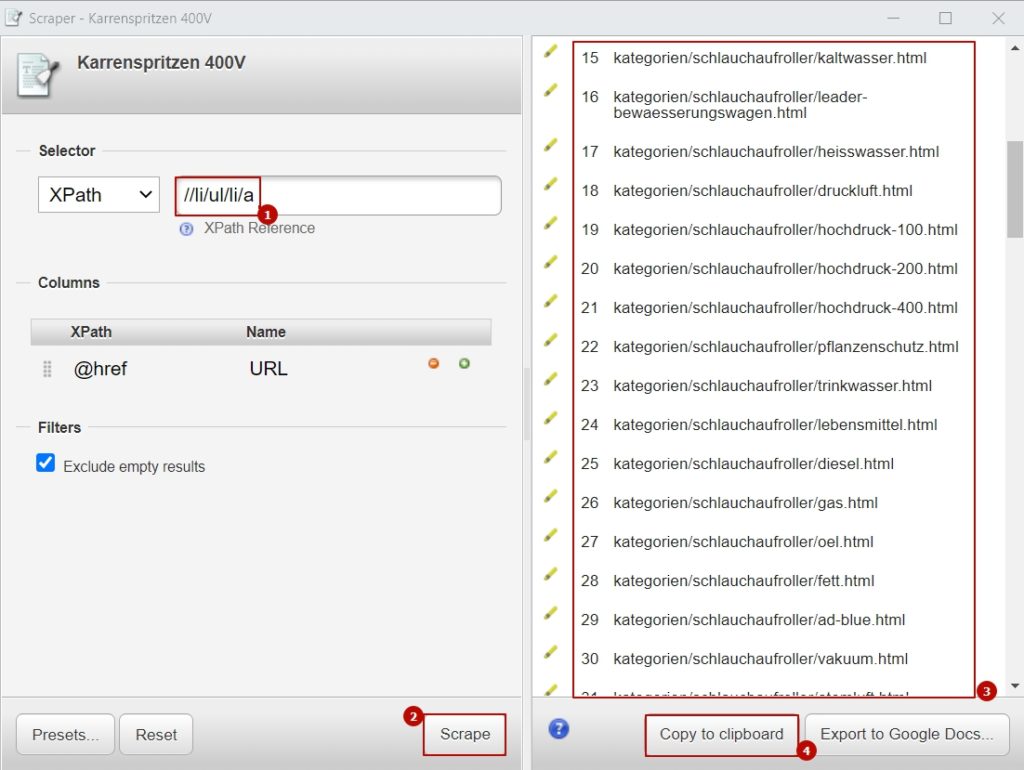
Now we have a categories file, categories.txt
Cheerio Crawler
Let’s copy a Cheerio Crawler from the Apify official site (do not forget npm i apify –save). As usual in a new folder we init node project and crate index.js file. Now we’ll customize the crawler. Let’s highlight its important features.
Init crawler queue with categories urls
The following code inserts categories links into the crawler request queue:
const lineReader = require('line-reader');
lineReader.eachLine('categories.txt', async function(line) {
let url = base_url + line.trim();
await requestQueue.addRequest({ url: url });
}); Main crawler function
handlePageFunction() is the main crawler function in index.js file that is called in order for each page to be fetched by a single request to perform the logic of the crawler.
Discern between (1) category page and (2) product page
Since we store both kinds of urls (category page and product page) into the same queue, when processing each inside a crawler, we need to apply if/else :
// detail page or category page ?
if (request.url.includes("/id-") {...}- From categories pages we retrieve pagination links and single product pages:
// add navigation links into requestQueue
$('.link').each((index, el) => {
requestQueue.addRequest({ url: base_url + $(el).attr('href').trim() , forefront: true });
});
// get product pages
$('h2 a').each((index, el) => {
requestQueue.addRequest({ url: base_url + $(el).attr('href').trim() });
}); - At the product page we retrieve product data and push it both in Apify dataset and in the custom array:
var images=[];
$('div.thumbnails figure.image_container a').each((index, el) => { images.push(base_url + $(el).attr('href').trim());
});
// Store the results to the default dataset. In local configuration,
// the data will be stored as JSON files in ./apify_storage/datasets/default
let item = {
url: request.url
, images: images
, name: $('div.details h1').text()
, sku: $('div.details div.sku').text().split(' ')[1]
, weight: $('div.details div.weight').text().split('Versandgewicht:')[1].trim()
, short_descr: $('div.details div.teaser').text()
, description: $('div.details div.description').text().replace(/[\n\t\r]/g," ").replace(/\s+/g," ").split('Beschreibung')[1].trim()
, price: $('div.details div.price div.sum').text().replace(/[\n\t\r]/g," ").replace(/\s+/g," ").trim()
, info: $('div.details div.price div.info').text().replace(/[\n\t\r]/g," ").replace(/\s+/g," ").trim()
, delivery_time: $('div.price div:nth-of-type(3)').text().split('Lieferzeit:')[1].trim()
};
await dataset.pushData(item);
total_data.push(item);Save results into CSV file
Since Apify stores data locally as JSON, and we need to deliver data as CSV, we’ll be using csv-writer package. The array where we push data is total_data.
Storing data into total_data array and later to CSV eliminates a need for using Apify’s own dataset, but we have still left it inside the crawler code.
Execution result and code repo
The result (~1500 entries) was fetched at local run thru asynchronous runs within a minute. The code repo is here: https://github.com/igorsavinkin/ebinger.
Conclusion
The Node.js asynchronous runtime environment offers a new era web development, where no threads are needed but parallel async runs do their excellent jobs.