I want to test a proxy [gateway] service. What would be the simplest script to check the proxy’s IP speed and performance? See the following script.
Categories
I want to test a proxy [gateway] service. What would be the simplest script to check the proxy’s IP speed and performance? See the following script.
We want to show how one can make a Curl download file from a server. See comments in the code as explanations.
// open file descriptor
$fp = fopen ("image.png", 'w+') or die('Unable to write a file');
// file to download
$ch = curl_init('http://scraping.pro/ewd64.png');
// enable SSL if needed
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
// output to file descriptor
curl_setopt($ch, CURLOPT_FILE, $fp);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
// set large timeout to allow curl to run for a longer time
curl_setopt($ch, CURLOPT_TIMEOUT, 1000);
curl_setopt($ch, CURLOPT_USERAGENT, 'any');
// Enable debug output
curl_setopt($ch, CURLOPT_VERBOSE, true);
curl_exec($ch);
curl_close($ch);
fclose($fp);
I develop a web scraping project using Selenium. Since I need rotating proxies [in mass quantities] to be utilized in the project, I’ve turned to the proxy gateways (nohodo.com, charityengine.com and some others). The problem is how to incorporate those proxy gateways into Selenium for surfing web?
test.py
import MySQLdb, db_config
class Test:
def connect(self):
self.conn = MySQLdb.connect(host=config.db_credentials["mysql"]["host"],
user=config.db_credentials["mysql"]["user"],
passwd=config.db_credentials["mysql"]["pass"],
db=config.db_credentials["mysql"]["name"])
self.conn.autocommit(True)
return self.conn
def insert_parametrized(self, test_value="L'le-Perrot"):
cur = self.connect().cursor()
cur.execute("INSERT INTO a_table (name, city) VALUES (%s,%s)", ('temp', test_value))
# run it
t=Test().insert_parametrized("test city'; DROP TABLE a_table;")
db_config.py (place it in the same directory as the test.py file)
db_credentials = {
"mysql": {
"name": "db_name",
"host": "db_host", # eg. '127.0.0.1'
"user": "xxxx",
"pass": "xxxxxxxx",
}
}
Today I needed to enable a Charles proxy on my Windows PC. Later I have managed the Genymotion virtual device to be monitored by the Charles proxy.
Given:
For SSH access in a terminal type:
then enter the password (testPass) at a password prompt.
The Python requests library is a useful library having tons of advantages compared to other similar libraries. However, as I was trying to retrieve the Wikipedia page, requests.get() retrieved it only partially:
Recently I decided to work with pythonanywhere.com for running python scripts on JS stuffed websites.
Originally I tried to leverage the dryscrape library, but I failed to do it, and a nice support explained to me: “…unfortunately dryscrape depends on WebKit, and WebKit doesn’t work with our virtualisation system.”
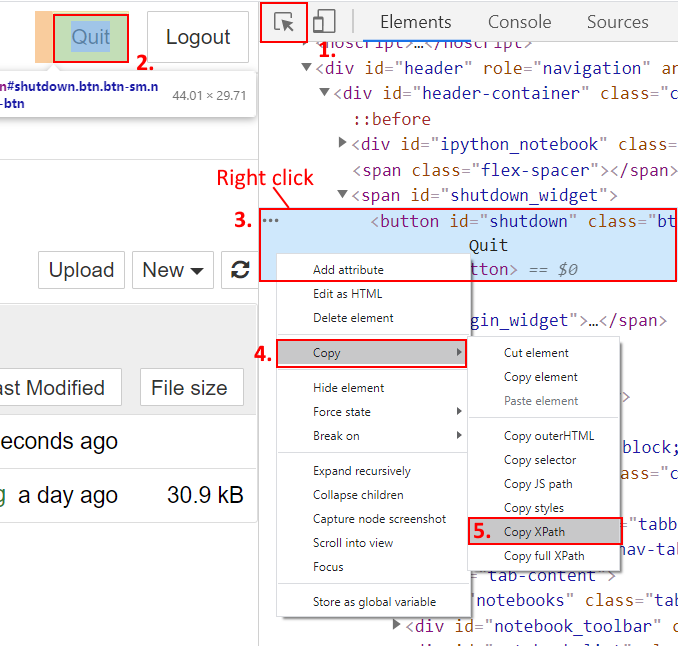
Often for the purpose of scraping, one needs to find certain elements’ XPath on a webpage. How can one do that with browser Web developer tools, aka Web inspector? A picture is worth of thousand words.