 Dexi.io is a powerful scraping suite. This cloud scraping service provides development, hosting and scheduling tools. The suite might be compared with Mozenda for making web scraping projects and runnig them in clouds for user convenience. Yet it includes the API, each scraper being a json definition similar to other services like import.io, kimono lab and parseHub.
Dexi.io is a powerful scraping suite. This cloud scraping service provides development, hosting and scheduling tools. The suite might be compared with Mozenda for making web scraping projects and runnig them in clouds for user convenience. Yet it includes the API, each scraper being a json definition similar to other services like import.io, kimono lab and parseHub.
Overview
In the nutshell the Dexi is a web enviroment for building and hosting web scraping robots. The scraped output is available both as JSON/CSV data and can also be queried through ReST from external applications. The web suite provides most of the modern web scraping functionality: CAPTCHA solving, proxy socket, filling out forms including dependent fields (drop downs), regex support and others. Robots also support the javascript evaluation for the scraped code.
The tool offers a point and click UI; no coding unless you need to handle javascript tricks :-). So for harder tasks you’ll sure need a programmer’s help. Eventually, the robot is boiled down to the JSON command definition containing meta and service info.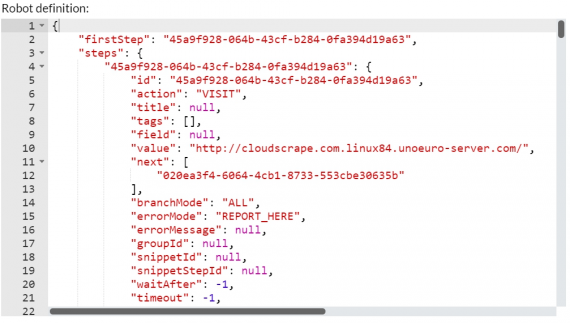
This is the modern js representation of the scraping robot as an object which can be easily edited, adjusted and transferred for other projects.
Robot building workflow
The robot building workflow is quite strightforward. You log in, choose Robot left pane tab and Create new Robot. Enter starting URL, name it and choose its type: Scraper or Crawler.
Following that you just utilize point-&-click UI to select page elements, choose actions, set before/after steps and more. Read more about the browser based robot building. See a robot example test results:
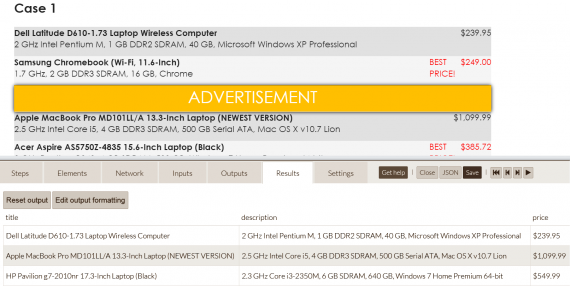
One may add on Crawler robot. It is formed based on conditions and processes. The crawling depth is adjustable. It took me quite a while to compose my first robot (mainly through watching tutorial videos).
Runs and execution
After the robot is ready you need to configure its run. Run is the configuration of how to excecute it comprising of concurrency, scheduling, integrations and inputs.
Robot execution happens in the cloud and results are stored in the available storage untill you wish to download, request through API or/and delete them.
Also I’d underline some more features the Dexi provides:
- The system operates with CSS and JQuery selectors. Better you get familiar with them.
- For each robot’s run a User-Agent might be set up.
- Robots.txt respect on/off for a single run.
- Execution of an original javascript at predefined moment of workflow (before, during or after workflow process) to make the site’s content available.
- The system produces screenshots at each extraction step to help debug what went wrong. (+1)
- Can extract images, file downloads and take screenshots of any element
Proxies
You should plug in 3rd party proxies to be used within Dexi tool.
“We do not allow running without proxies so if your account has no proxies – we will use our free proxies for your executions.”
They now have over 160 proxies (61 DE proxies and 100 US proxies), so you might need need to plug in the 3rd party proxy service for professional web scraping.
API
As the modern cloud scraper tool it works to be monitored, executed and fetched results thru ReST API. More details here. So your results might get fetched by a simple php code:
$runId='';
$accountId='';
$apiKey='';
$request_url = "https://app.dexi.io/api/runs/$runId/latest/result";
$accessKey = md5($accountId . $apiKey);
$request = array(
'http'=> array(
'method'=> "GET",
'header'=> "X-DexiIO-Access: $accessKey\r\n" .
"X-DexiIO-Account: $accountId\r\n" .
"Accept: application/json\r\n" .
"Content-Type: application/json\r\n" .
"User-Agent: Mozilla/5.0 (iPad; U; CPU OS 3_2 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML, like Gecko) Version/4.0.4 Mobile/7B334b \r\n"
)
);
$context = stream_context_create($request);
$response = file_get_contents($request_url);
$results = json_decode($response, false, $context);
$runId – get it through API Runs get method (might also be available when you edit each run).
$accountId – see it at your personal API page.
$apiKey – generate one through personal API page
CAPTCHA
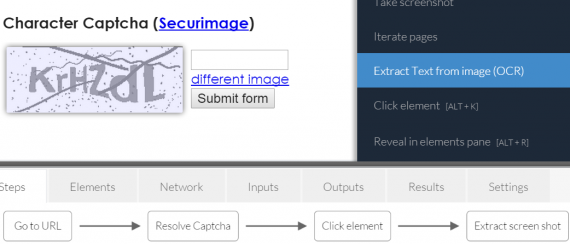
The Dexi now provides a built-in CAPTCHA solving service that at the moment (July 2015) is free of charge for the SaaS users. Which is something you rarely see in scrapers. Yet, the service is able to solve only the input field CAPTCHA s (not JS-driven CAPTCHAs: draggable, drag and drop & etc.). The following are the steps (as suggested by their support) detailing how to set CAPTCHA solving steps in robot:
Just point to the image from the captcha, and select ‘Add step for element’. Click on the step in the timeline, and click ‘edit step’. In the ‘Type’ selector choose ‘Resolve Captcha’. Then select the ‘Captcha Input’ by selecting the icon and afterwards point it to the input field on your page. Finally add a step, which click the submit button.
Integration
The system provides the variety of exporting options. For that you follow the Integration sign. Select integrations and formats for each run. These will be invoked automatically whenever an execution of this run succeeds.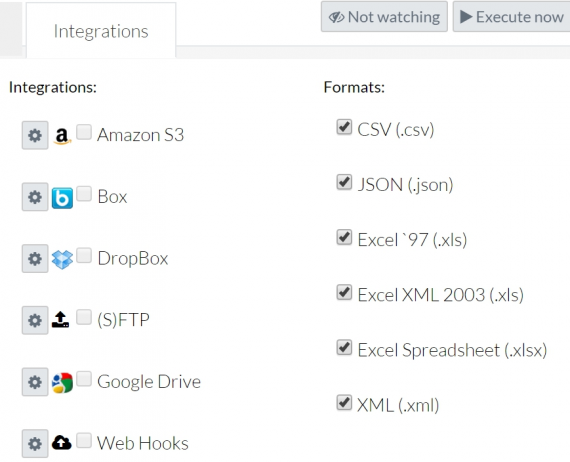
Pricing and counting
The Dexi SaaS offers a free account with feature full functionality, execution time being limited to 1 hour and concurrent robots (workers) being limited to 10 only. But for pro usage you do need to upgrade to the paid plan that start at $119/month with unlimited workers, unlimited execution time and full feature access. Dexi also provides on-demand pricing where you can opt to pay only for the execution hours you use.
Conclusion
My impression of the Dexi web scraping suite is that it is a modern environment for building and hosting scrapers. It offers users the “gentleman set” for the web scraping, which is not provided by any similar tool. Their CAPTCHA solving sets Dexi apart from services like Import.io or Kimono. Compared to Mozenda, this suite is more convenient purely because it is fully browser based (Mozenda requires you to install a desktop agent builder).
The docs are still under development, but a learning curve doesn’t appear to be too steep. Their support is very responsive and always ready to assist you. It looks modern, developing and it will sure have its place among the other scrape tools and frameworks.
5 replies on “Dexi.io Review”
This is a really nice software, but you are right, it REALLY does lack documentation and tutorials at the moment.
Agreed with Tom, Indeed good article.
i want scrap some information from the aliexpress website … It is possible ..? if it is possible what should i do for that ?
Consider this post
Hi.
I really need help in data crapping.
Doreee1212@gmail.com