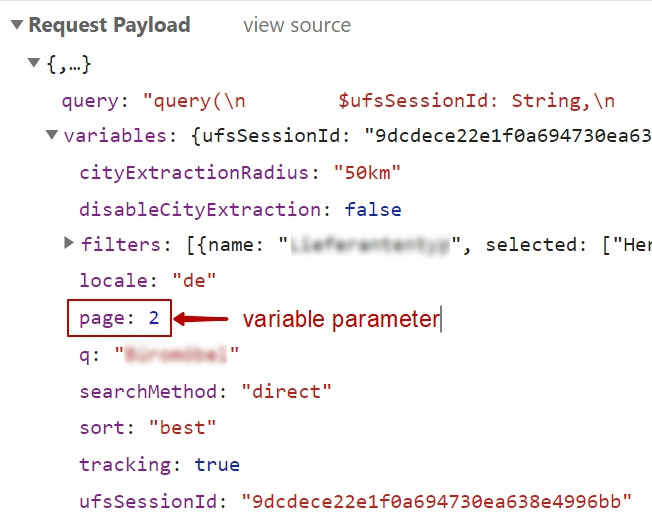
Recently i was challenged with getting Linkedin group memebers info. The challenge made me to seek some ways to
Here is a video where I try to catch all Linkedin group members through endless scroll**, I having to be a member of the group.
The real speed is ~1 person/second though.
Sometimes you need to click on the “Scroll more results” button or even just hover the mouse over this button.
Automate scroll
**The post on how to start infinite scroll in the browser… But this JS code from the post does not help to replenish the page… Only when there is a focus on the browser tab/page, the script continues loading data again.