
Scraping youtube comments has become crucial if you are working on some sentiment analysis project. The comments section will give you an overview of the public sentiment toward any election or sports results, scams, wars, etc. Comments reflect an overall feeling of a person. What according to them is right and wrong is mentioned in the comments.
In this tutorial, we will show how to scrape comments from a youtube video using Python and Selenium. At the end of this tutorial, you will have a list of comments from this video which can later be fed to any NLP model.
Setting up the prerequisites
I am assuming that you have already installed Python 3.x on your machine. That being said let’s create a folder where we will store our python script.
mkdir youtube_scraperNow, install libraries that are required to scrape youtube.
pip install selenium
pip install beautifulsoup4Selenium will help us to automate our web scraping. It offers APIs through which we can render websites.
BeautifulSoup will help us to parse out crucial data from the raw data.
Chromium — This is a webdriver that is used by Selenium for controlling Chrome. You can download it from here.
Create a file inside the project folder where we will write our code. I name the file index.py. You can use any name you like. Everything is set now. Let’s scrape comments now.
Scraping Youtube Comments
Let us first run a small test by opening the target youtube URL on the chrome browser to confirm everything works correctly.
from bs4 import BeautifulSoup from selenium import webdriver import time PATH = 'C:\Program Files (x86)\chromedriver.exe' target_url = "https://www.youtube.com/watch?v=5hFd6zGkxLE" driver=webdriver.Chrome(PATH) driver.get(target_url) time.sleep(2) driver.close()
First, we have imported all the libraries like Selenium, beautifulSoup, and time. Then I declared the PATH variable. PATH variable holds the location of the chromium web driver. After this, I declared the target URL and created a chrome instance using webdriver.Chrome(). The .get() method will open the web page with the youtube video and .close() will close the chrome browser. It’s a pretty straightforward code and simple to understand.
Once you run this code it will open a chrome browser and in a few seconds our target URL will load. We have applied a 2-second delay to make the page load completely. After the two seconds browser will close. After this, we can say our setup is complete and we can move ahead to scrape youtube comments.
The following is an example of what the chrome window would appear as upon a successful execution:
What to Scrape?
Our main focus in this tutorial is on the comment section. Using selenium we will extract the raw data. Then by using find() and find_all() methods of BS4 (BeautifulSoup) we will find crucial data points within that raw data. The choice of method to locate an element would depend on the structure of the DOM and what method is most suitable for the specific scenario.
Scrape Comments
First of all, we have to identify the location of the comment section. We can easily do this by using XPath.
Xpath, which stands for XML Path Language, is a method for selecting specific nodes from an XML document. Detail article on Web Scraping with Python and Xpath can help you understand how exactly Xpath works.

We will use find_element_by_xpath method provided by the Selenium webdriver in order to locate any element on the page. In place of this, you can also use find_element_by_id.
But there is a catch and the catch is when you open the Chromium browser through Selenium, comments will not be visible at first on your screen. To load comments you have to scroll down. For this, we will use the execute_script function to scroll down the youtube page.
driver.maximize_window()
time.sleep(2)
for i in range(0,7):
time.sleep(2)
driver.execute_script("window.scrollTo(0, 10000);")At first, we have maximised the size of the window, and then after waiting for four seconds, we scroll down a bit to load the comments, and then after this, we are continuously scrolling down after waiting every 2 seconds.
The web page will look something like this.
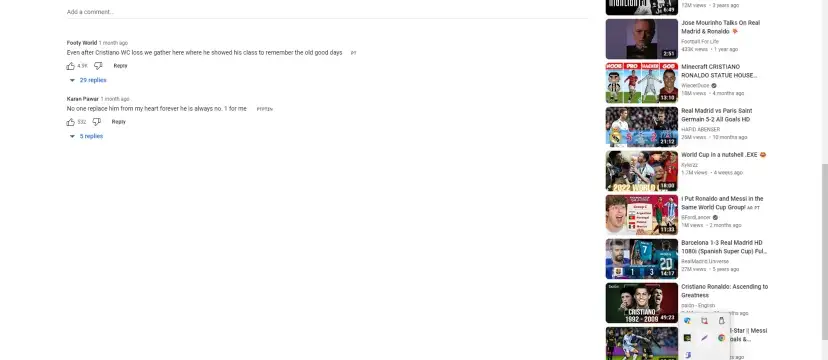
Now after this, we are going to use the find_element_by_xpath function to find any tag with id whose value equals comments as shown in the image above.
comments_section = driver.find_element_by_xpath('//*[@id="comments"]')
Now, since we have located the target element, let’s extract the HTML content from that. We will use the get_attribute() method to extract the innerHTML from the comment_section node.
# extract the HTML content of the comments section
comments_html = comments_section.get_attribute('innerHTML')
Raw data are ready now. We can pass this data to BeautifulSoup in order to parse out comments.
# parse the HTML content with BeautifulSoupsoup = BeautifulSoup(comments_html, 'html.parser')
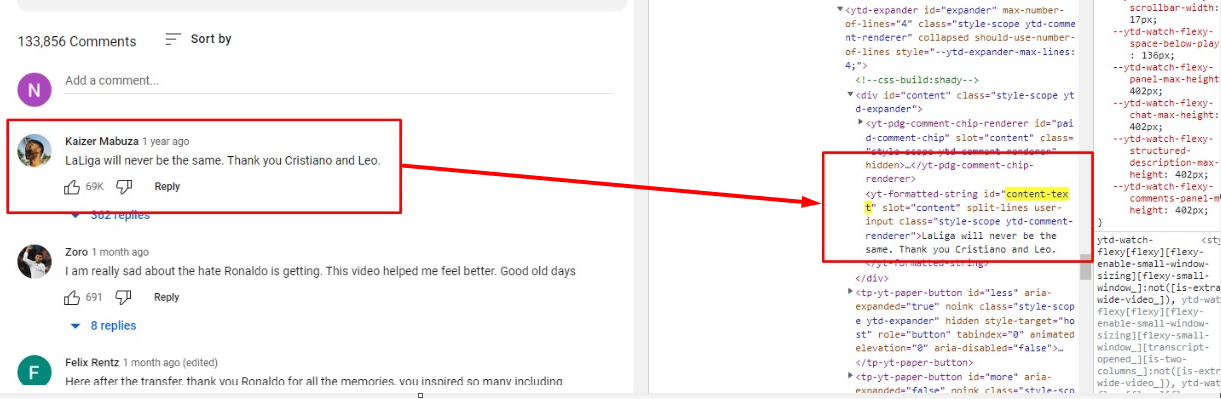
For loop will be able to reach each and every comment available on the screen. In this image, we can see yt-formatted-string tag with class “style-scope ytd-comment-renderer” holds the comment.
We add .encode("utf8") for the sake of proper encoding of the non-ascii characters to be printed out.
# extract the text of the commentscomments = [comment.text.encode("utf8") for comment in soup.find_all('yt-formatted-string', {'class': 'style-scope ytd-comment-renderer'})]
The comments will be a list of comment texts available on the screen. Once you print out this it will look like this:
[‘LaLiga will never be the same. Thank you Cristiano and Leo.’, ‘He is not just a player.\nHe is an emotion.’, ‘Ronaldo absolutely made history in Madrid, imagine if he never left’, ‘Ver este video hace que me ponga triste y le doy gracias a Dios por nacer en la época del mejor jugador de esta época \nGracias cr7 por todo, y para mi es el goat del fútbol 🇵🇹\nG : goleador incansable \nO : otro planeta \nA : animal competitivo \nT: talento con esfuerzo y disciplina’, “Hate him or Love him.\nBut, you cannot ignore him.\nHe is a class.\nWorld gonna miss him :'(“, ‘Ya 5 años desde que se fue y aun no lo supero ‘, ‘451 goals in 438 matches plus ‘…]
Complete Code
With just a few more lines of code, you can extract information like title of the video, number of likes, number of comments, etc. Youtube is a data-rich video platform that can give you a clear picture of public sentiment toward any event around the globe. You can load more comments by adding time.sleep and driver.execute_script commands.
But for now, the code will look like the following.
from bs4 import BeautifulSoup
from selenium import webdriver
import time
PATH = 'C:\Program Files (x86)\chromedriver.exe'
target_url = "https://www.youtube.com/watch?v=5hFd6zGkxLE"
driver=webdriver.Chrome(PATH)
driver.get(target_url)
driver.maximize_window()
time.sleep(4)
for i in range(0,7):
time.sleep(2)
driver.execute_script("window.scrollTo(0, 10000);")
comments_section = driver.find_element_by_xpath('//*[@id="comments"]')
# extract the HTML content of the comments section
comments_html = comments_section.get_attribute('innerHTML')
# parse the HTML content with BeautifulSoup
soup = BeautifulSoup(comments_html, 'html.parser')
# extract the text of the comments
comments = [comment.text.encode("utf8") for comment in soup.find_all('yt-formatted-string', {'class': 'style-scope ytd-comment-renderer'})]
# print the comments - optional
print(comments)
driver.close()Conclusion
This article covered the topic of scraping data from YouTube using Selenium. It introduced the concept of XPaths and how they can be applied in web scraping. Additionally, you can also use web scraping APIs to prevent any kind of IP bans while scraping youtube at scale.
The steps outlined in the article can be applied to extracting data about individual videos or scraping search results from YouTube. The code can also be used in combination with some other tools to download selected videos for offline viewing.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on your social media.