
Screen Scraper is a classical scraping tool for all kinds of data scraping, extracting and packing. However, it takes time to properly master it.
Overview
Screen Scraper is a full-kit development lab for scraping, analyzing and saving data for midsize or large scale projects. Screen Scraper works using a Regex data extraction approach. Screen Scraper is issued in 3 editions: Basic, Professional and Enterprise. The first being free spread, while the last ones provide a powerful pro API tools for data extraction and system integration. As we were using Screen Scraper, it worked as a stable, inclusive software, able to do all kinds of tasks. The 7 rich tutorials clearly show how to construct a data extraction project.
Workflow
Screen Scraper defines its extraction patterns using a built-in proxy. First, you need to configure the proxy of your browser so that the data flow will go through the Screen Scraper (see tutorial 1). Turn the proxy on and create and start a new proxy session on SS:
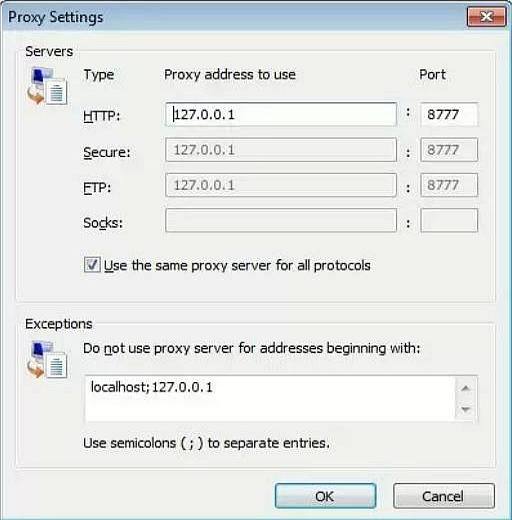
Actually, after I turned the proxy on, there was a big confusion of warnings issued by Google Chrome on certificates that came in from the web. I turned the proxy off and everything went smoothly. The problem is that since HTTPS requires encryption certificates, web browsers alert on certificates not properly signed. Screen Scraper, as a proxy, evidently cannot provide the proper certificate. So browsers often reject or ask permissions for the HTTPS, when Screen Scarper is on as a proxy. To use it as a proxy, Opera browser is recommended for sites using HTTPS. Screen Scraper downloads the main page content and all sub-links during the proxy session. After that, you need to set the proxy off. When you turn the proxy off there should be no more trouble with HTTPS.
The following picture shows the HTTP transactions going through the proxy and being stored:
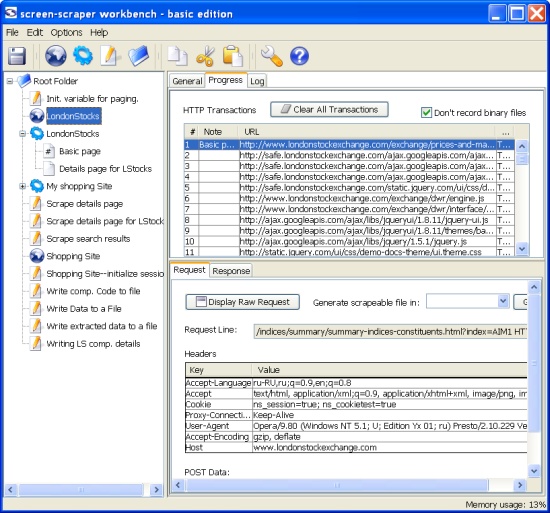
Then, you need to create a scraping session. The data ripped from the web during a proxy session will generate a scrape-able file, as part of a scraping session. The scraping session strips the web and applies patterns to the data:
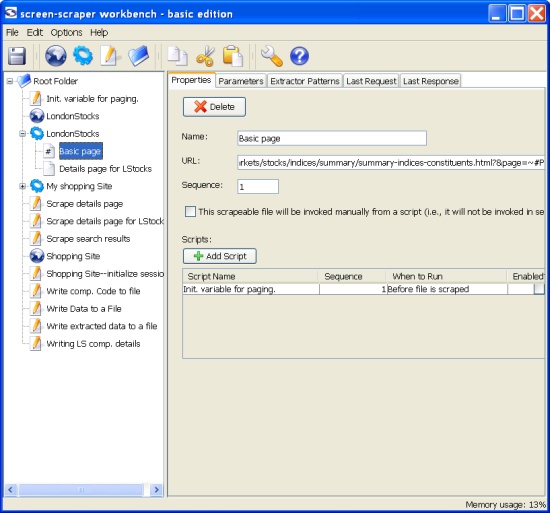
Scrapeable files are just containers to accommodate links to the web data, extraction patterns and following scripts. Scrapeable files are launched during the scraping session (mainly in a sequence). The browser requests the target page by the link and the program applies pre-set extraction patterns and following/preceding scripts. To make an extraction pattern, you need to search through HTML shown at the “Last Response” tab of the scrape-able file, using the “Find” tool. After defining the area for the pattern, just right click the mouse button and follow the prompted “generate the extraction pattern”:
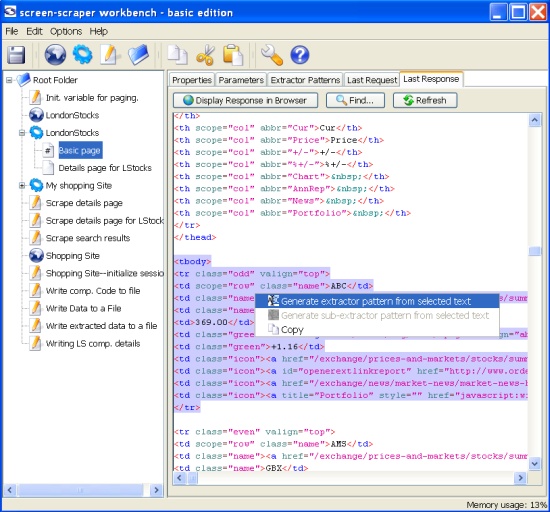
As you can see from the picture, Screen Scraper provides convenient tools to set up extraction patterns and to define extraction tokens. Thus, you may define extraction tokens, and conveniently, one may test each pattern right there. If you are skilled in Regex, you might write your own Regexes for tokens:
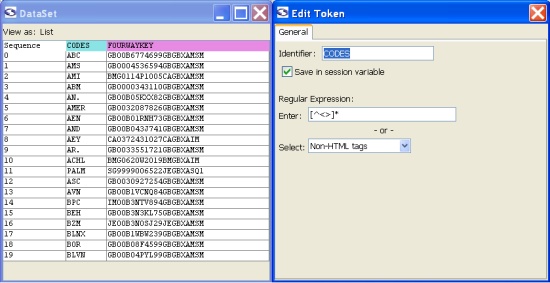
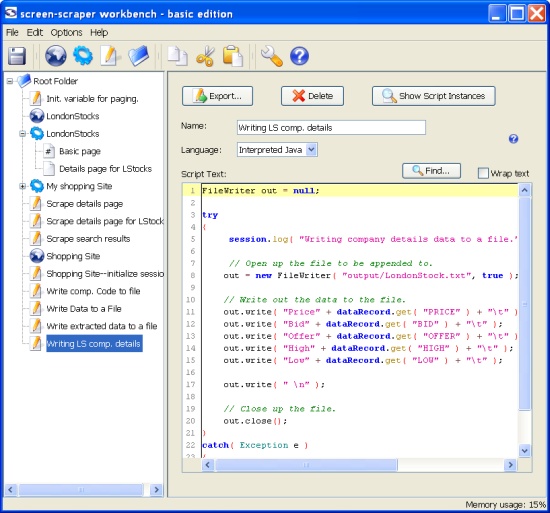
After setting up the patterns and tokens, you need to save data to a file or somewhere else. The scripts serve this purpose. They may follow the patterns’ matches during the session, or they precede the session in order to set up session variables, or be invoked at other times. Here is a simple output script in Interpreted Java (the JavaScript and Python languages are also supported by Screen Scraper for writing scripts):
Summary
Screen Scraper is a good tool to work with all kinds of data mining, including dynamic pages. Yet, it takes much time for an inexperienced user to master the techniques. Therefore, the best way is to call upon a scraping guru. The important thing is that Screen Scraper can integrate with other systems, with Java support allowing you to write serious scripts for a large scale program.
One reply on “Screen Scraper Review”
GrabzIt also provides an online screen scraper (www.grabz.it/scraper) tool that allows you to easily scrape websites, without much technical knowledge.