Tag: Selenium
Selenium comes with a default WebDriver that often fails to bypass scraping anti-bots. Yet you can complement it with Undetected ChromeDriver, a third-party WebDriver tool that will do a better job.
In this tutorial, you’ll learn how to use Undetected ChromeDriver with Selenium in Python and solve the most common errors.
Categories
How to bypass PerimeterX
You’ve found the website you need to scrape, set up your scraper and fired it, just to sadly realize PerimeterX has blocked you.
PerimeterX’s dynamically complex bot detection system relies on server-side and client-side checks to distinguish humans from bots. It deploys several layers of protection and, for the most part, manages to do its job without interrupting the user experience.
But don’t fall into despair! There are a couple of things you can try to bypass PerimeterX (called HUMAN now) before giving up on your goal of scraping that delicious data.
Recently we’ve got the tricky website, its data being of dynamic nature. Yet we’ve applied the modern day scraping tools to fetch data. We’ve develop an effective Python scraper using Selenium library for browser automation.
About the project
We were asked to have a look at a retailer website.
And our task was to gather data on 210 products’ availability in 945 shops. The scrape resulted in about 200K data entries in a CSV format. Moreover, every line contained information about name, link, brand, store and the availability of a product. Below you can familiarise yourself with a small data sample we were able to gather.

Scraping youtube comments has become crucial if you are working on some sentiment analysis project. The comments section will give you an overview of the public sentiment toward any election or sports results, scams, wars, etc. Comments reflect an overall feeling of a person. What according to them is right and wrong is mentioned in the comments.
We’ve got some code provided by Akash D. working on ticketmaster.co.uk. He automates browser (Chrome as well as Edge) using Selenium with Python. The rotating authenticated proxies are leveraged to keep undetected. Yet, the site is protected with Distil network.
In this post we share with you how to perform web scraping of a JS-rendered website. The tools as seen in the header are JAVA with Selenium library driving headless Chrome instances (download driver) and JSoup as parser to fetch data of the acquired HTML.
Categories
Selenium Web Scraping in simple words
 Question: What is Selenium web scraping?
Question: What is Selenium web scraping?
Answer: A picture is better than 1000 words: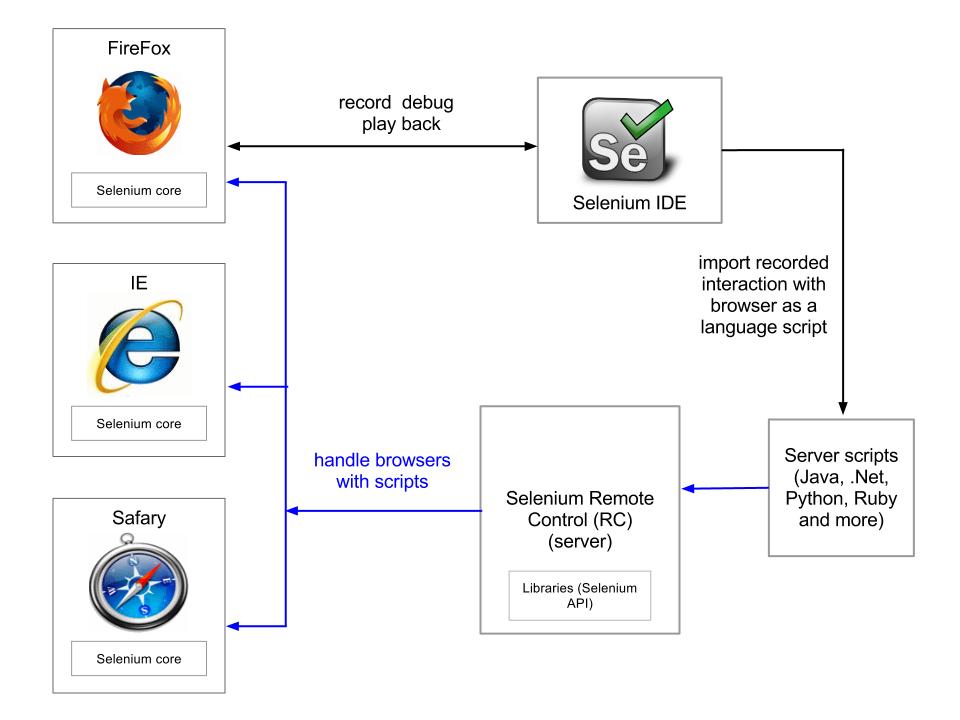
So, you make a program with Python, PHP, JAVA, Ruby and whatever language you use in order to browse(), select(), click(), submit(), save(), etc., target web pages.
Since Selenium WebDriver is created for browser automation, it can be easily used for scraping data from the web. In this post we will consider some advantages and drawbacks of using WebDriver for web scraping.
Recently I’ve got a question:
How do I get pass the dynamic “load more” button using a Python web scraper?