In a previous post we’ve considered the ways to disguise an automated Chrome browser by spoofing some of its parameters – Headless Chrome detection and anti-detection. Here we’ll share the practical results of Fingerprints testing against a benchmark for both human-operated and automated Chrome browsers.
Author: Igor Savinkin
In the post we summarize how to detect the headless Chrome browser and how to bypass the detection. The headless browser testing should be a very important part of todays web 2.0. If we look at some of the site’s JS, we find them to checking on many fields of a browser. They are similar to those collected by fingerprintjs2.
So in this post we consider most of them and show both how to detect the headless browser by those attributes and how to bypass that detection by spoofing them.
See the test results of disguising the browser automation for both Selenium and Puppeteer extra.
In this post we’ll share with you the vivid yet simple application of the Linear regression methods. We’ll be using the example of predicting a person’s height based on their weight. There you’ll see what kind of math is behind this. We will also introduce you to the basic Python libraries needed to work in the Data Analysis.
The iPython notebook code
Often at scraping I collect images or other sequential elements into an array. Yet, afterwards I need to remove duplicate elements from an array. The magic is to make it a Set and then use Spread syntax to turn it back to array.
links = [];
$('div.items').each((index, el) => {
let link = $(el).attr('href');
links.push(link);
});
// remove repeating links
links = [...new Set(links)]See also How to remove from an array empty or undefined elements.
Often at scraping I collect images or other sequential elements into an array. Yet, afterwards I need to remove empty elements from it.
images = [];
$('div.image').each((index, el) => {
let url = $(el).attr('src');
images.push(url);
});
// remove invalid images
images = images.filter(function(img){
return img && !img.includes('undefined')
});See also How to remove from array duplicate elements.
When performing web scaping I first need to evaluate a site’s difficulty level. That is how difficult is it for the scrape procedures? Do its pages make extra XHR (Ajax) calls? Based on that I choose whether to use (1) Request scraper (eg. Cheerio) or (2) Browser automation scraper (eg. Puppeteer).
So, I’ve discovered an Apify Web Page Analyzer, a free scraper agent that analyses a target site and returns inclusive JSON data of the target web page. The presence of XHR (AJAX) helps me to decide what type of crawler to use for scraping that website.
In the post we share some basics of classification and clustering in Machine learning. We also review some of the cluster analysis methods and algorithms.
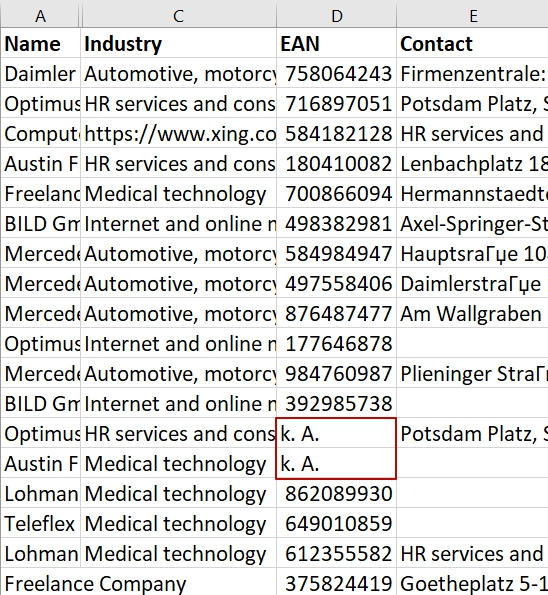
Working with generated UTF-8 files it’s a challenge to view them properly in Excel. Gladly there is a method how to properly open them in Excel.
In this post we share how to plot distribution histogram for the Weibull ditribution and the distribution of sample averages as approximated by the Normal (Gaussian) distribution. We’ll show how the approximation accuracy changes with samples volume increase.
One may get the full .ipynb file here.
Categories
Invalid data, what it is?
Often we see “invalid data”, “clean data”, “normalize data”. What does it mean as to practical data extraction and how does one deal with that? One shot is better than 1000 words though: