

Recently we encountered a website that worked as usual, yet when composing and running scraping script/agent it has put up blocking measures.
In this post we’ll take a look at how the scraping process went and the measures we performed to overcome that.
A scraping agent
At first we composed the scraping agent with JAVA using JSoup library. At the test phase the agent worked fine to reach both category and product pages.
The firewall blockage
Then when we added all other necessary selectors for parsing information to the agent and ran it, a firewall stopped the scraping process, namely the agent got no more than 17 product pages. We couldn’t access the site at all. The return page was as follows:
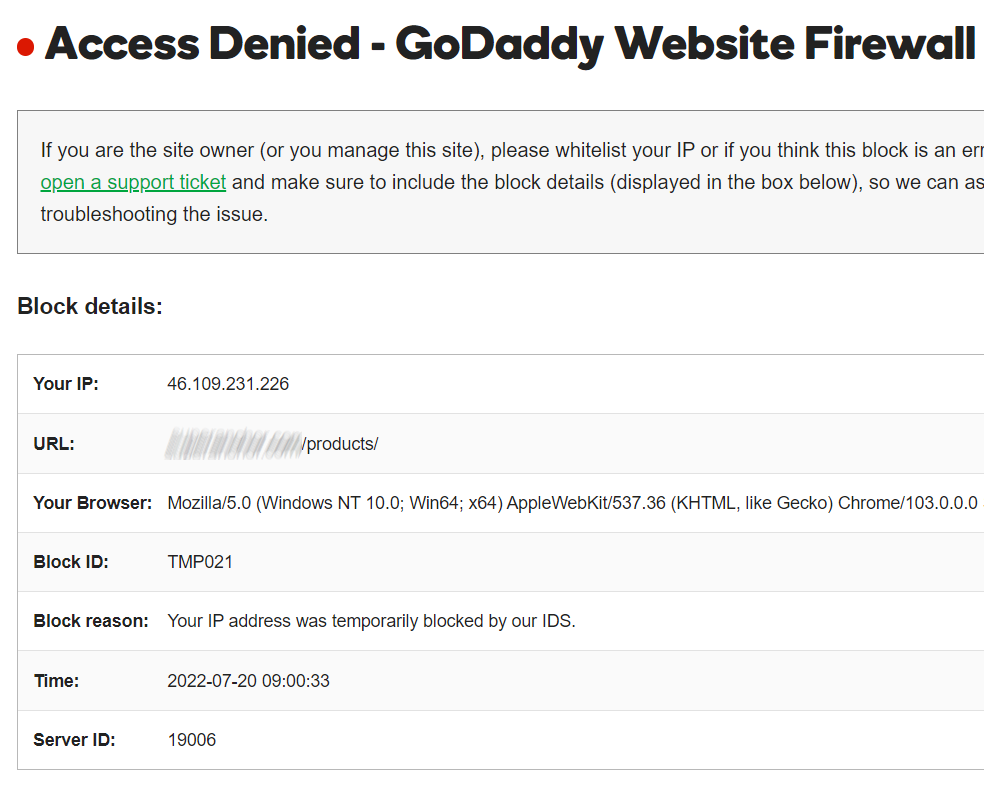
I took a look at the GoDaddy Firewall service. The advanced firewall plan included the following (I’ve bolded the aspects pertaining to the web scraping):
- Firewall prevents hackers.
- DDoS protection, and Content Deliver Network (CDN) speed boost.
- SSL certificate included in firewall.
- Protects one website.
- Malware scanning.
- Unlimited site cleanups
No details are given of what particularly the firewall performs. As we’ve searched for CDN hints in the website code, we’ve found none of those.
VPN & Browser Automation
We turned to the VPN usage when the site access was restored. The free VPN account has provided only a limited access to the target site. 🙁
Additionally we have switched from mere HTTP GET requests (by JSoup) to the browser automation.
We reached a full site access with the scrape agent by using a paid VPN plan (shuffling servers several times) and having a delay of 1.5 seconds.
Recap
The modern hustings now leverage hosting firewalls, yet they basically do general protection, based on the multiple access from the same IP. Managing VPN and browser automation makes it possible to overcome that blockage and bring in successful data harvest.