I’ve met with the challenge that composer failed to load guzzle library file:
https://packagist.org/p/guzzlehttp/guzzle%241f150aaa79afd8bc5d6f08f730634a0d60 f5dfcd1dd4a6fc5263fb4b1cefeb16.json" file could not be downloaded (HTTP/1.1 404 Not Found)
The solution has been the following:
composer clear-cache

 Question: What is Selenium web scraping?
Question: What is Selenium web scraping?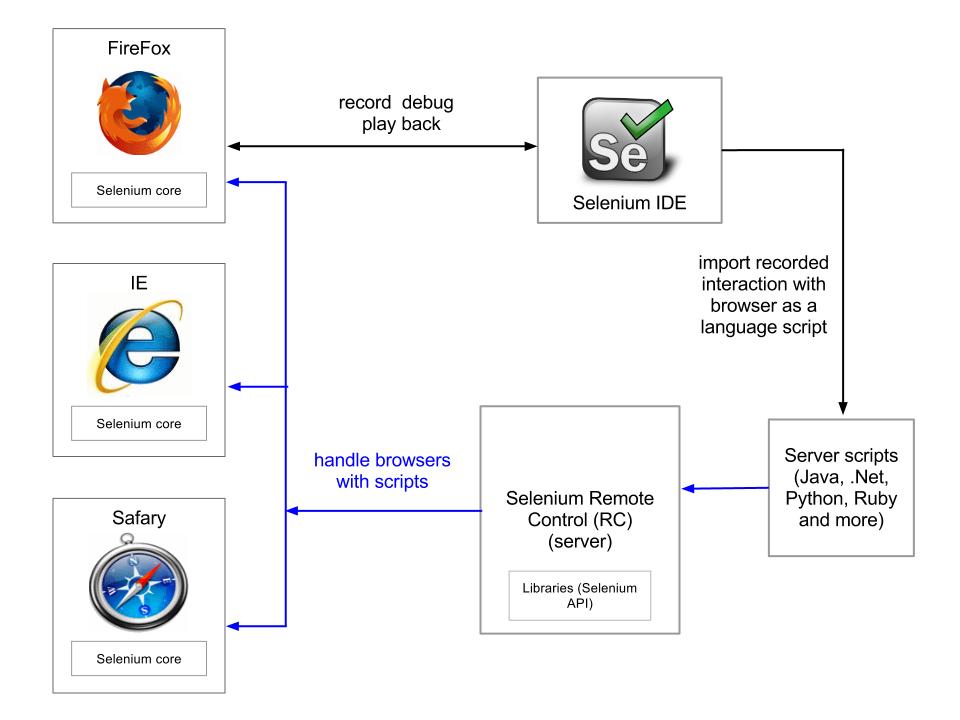

 My goal was to retrieve data from a web business directory.
My goal was to retrieve data from a web business directory.