Crawlee is a free web scraping & browser
automation library fitting for composing Node.js (and Python) crawlers.

I want to share with you the practical implementation of modern scraping tools for scraping JS-rendered websites (pages loaded dynamically by JavaScript). You can read more about scraping JS rendered content here.
Lately I needed to scrape some data that are dynamically loaded by “Load more” button. A website JavaScript invokes XHR (or Ajax request) to fetch a next data portion. So, the need was to re-run those XHR with some POST parameters as variables.
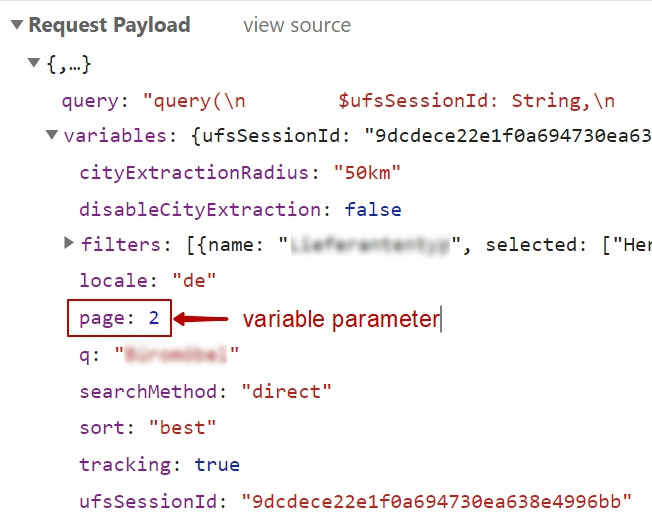
So, how to make it in Node.js?
Today, I got in touch with the Node.js [and Python] bots garden/zoo providing modern bots with different kinds of browsers (Firefox, Chrome, Headless/not headless) using different automation frameworks (Puppeteer, Selenium, Playwright) in several programming languages.
Recently we’ve got a tricky website of dynamic content to scrape. The data are loaded thru XHRs into each part of the DOM (HTML markup). So, the task was to develop an effective scraper that does async while using reasonable CPU recourses.

The MERN stack is a set of frameworks and tools used for developing a software product. They are very specifically chosen to work together in creating a well-functioning software (see a MERN app code at the post bottom).
node.exe index.js > scrape.log 2>&1
When executing file index.js we redirect all the console.log() output from console into a file scrape.log .
let table = $('table');
if ($(table).has('br')) {
$("br").replaceWith(" ");
}
In the previous post we shared how to disguise Selenium Chrome automation against Fingerprint checks. In this post we share the Puppeteer-extra with Stealth plugin to do the same. The test results are available as html files and screenshots.